Multi-label Classification using Deep Learning and Graph Embedding
for those impatient
project motivation
I want to build multi-label topic classifier for documents.
for example, in stackoverflow (so), each question has one or more tags:
in addition, I have two goals in mind:
- use deep learning techniques such as CNN for classification task.
- leverage the internal network structure among documents. For example, SO questions connect to other questions and via users.
formulation
deep learning for multi-label classification
for the first goal, it can be formulated as a multi-label classification problem. and I decided to use a variant of KimCNN.
this variant is decribed in this paper
graph embedding
for the second goal, I decided to use the recent popular graph embedding techniques.
graph embedding methods learn a lower dimensional representation for each node in the graph. specifically, i chose one of the earliest methods, deepwalk.
putting them together
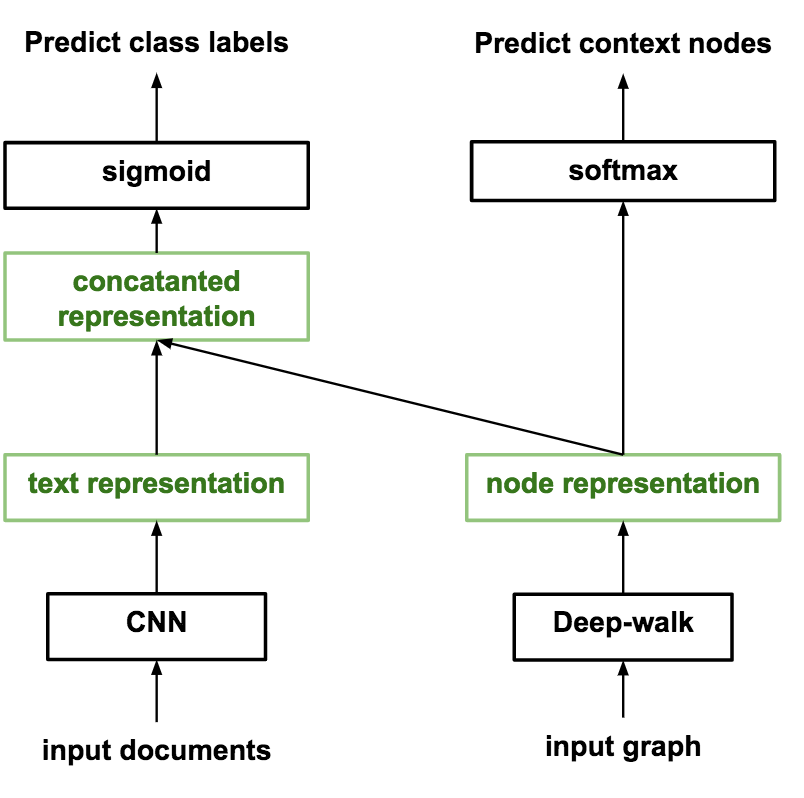
having these two components ready, for each document, we can derive a text representation (from CNN) and a node representation.
Then I concatenate them to predict to output label. meanwhile, node embedding is trained to predict each node’s context nodes.
The whole architecture is as folllowed:
implementation
I implemented the code using Python and tensorflow
- for the cnn part, I based my code mainly on this implementation
- for the deepwalk part, as it’s essentially word2vec in the graph context. I borrowed the code from this word2vec implementation in tf
the code (including experiment) can be accessed here
training
the training is done by alternating the update between supervised part and unsupervised part.
experiment
I did some experiment to validate the effectiveness.
methods
I considered three methods:
- fastxml: a tree-based multi-label classifier, for which I used tf-idf feature
- kimcnn: one slight difference compared to original verion, it uses sigmoid as output function instead of softmax. this design choice is discussed in here
- kimcnn + deepwalk: our method described above.
dataset
I downloaded and processed three sites from stackexchange:
data statistics are as follow:
| data science | emacs | software engineering | |
|---|---|---|---|
| #instances | 5145 | 4536 | 10336 |
| #labels | 327 | 618 | 1344 |
| avg #labels per instance | 2.7 | 2.0 | 2.6 |
graph construction
two questions are connected if they share at least one common user. a user might post/comment a question.
evaluation method
I consider precision at k as it’s more appropriate for this task that accuracy.
experiment result
data science
| fastxml | cnn | cnn+deepwalk | |
|---|---|---|---|
| p@1 | 0.26 | 0.53 | 0.57 |
| p@3 | 0.17 | 0.37 | 0.38 |
| p@5 | 0.15 | 0.29 | 0.28 |
emacs
| fastxml | cnn | cnn+deepwalk | |
|---|---|---|---|
| p@1 | 0.21 | 0.58 | 0.56 |
| p@3 | 0.10 | 0.30 | 0.30 |
| p@5 | 0.07 | 0.20 | 0.20 |
software engineering
| fastxml | cnn | cnn+deepwalk | |
|---|---|---|---|
| p@1 | 0.06 | 0.41 | 0.43 |
| p@3 | 0.06 | 0.26 | 0.25 |
| p@5 | 0.05 | 0.18 | 0.18 |
it seems that cnn+deepwalk does not work as good as I expected (I expect it to be better than cnn)
possible reasons
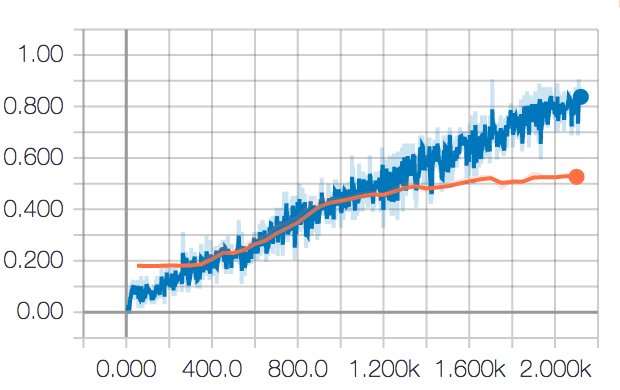
embedding does not help as much can be demonstrated in the following figure:
first is the training performance figure for CNN, where the x-axis is the training step and y is the p@1 score.
second is the similar figure but for cnn+deepwalk
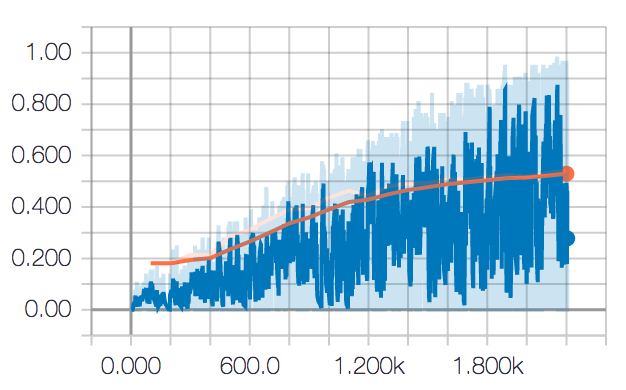
as we can see training score flactuates quite violently. I think this is a sign that emebdding interferes the supervised training part.
future work
first, the embedding part should be improved. I need to take more time to understand how can it help? and why can it help? is it because I constructed the graph inappropriately?
second, the current prediction requires evaluating each label which might be slow if large label space is large (many unique labels). it would be good if the prediction can be faster.
conclusion
- I got a chance to learn tensorflow and make it working for some task, which is very enjoyable
- tensorboard, the idea of visualizing computation graph, training summary and checkpoints is cool and handy
- cnn’s performance is really surprising compared to fastxml (a tree-based algorithm)
besides,
- tensorflow is not easy to debug (error message is not very readable).
- I encountered memory leaks which anoyed me a long time.
- the final solution is to add
sess.graph.finalize()when the graph is contructed - if new node are created (causing leaks) after
finalize(), exception is thrown
- the final solution is to add
